心智观察所: 离体脑细胞学会打游戏, 智能从何而来?
心智观察所:离体脑细胞学会打游戏,智能从何而来?
2022年,澳大利亚初创公司Cortical Labs联合多所高校在《Neuron》期刊上发表实验,展示离体脑细胞在芯片上成功玩《Pong》游戏并快速学习。
实验中,来自老鼠胚胎或人类干细胞的脑细胞在指甲盖大小的芯片上形成微型“脑组织”,通过电信号与游戏互动。
神经元通过电脉冲接收视觉信息,实时调整球拍位置,形成闭环反馈系统。
研究利用自由能原理,设计反馈机制,让神经元自发调整放电模式以减少“意外”,实现无监督学习。
实验结果表明,只有处于闭环反馈中的神经元表现出学习能力,验证了其适应性和学习机制。
[文/观察者网专栏作者心智观察所]
近年来,随着大语言模型的爆发式发展和生成式人工智能的广泛应用,人们一度认为硅基计算——即由晶体管、芯片和算法构成的传统人工智能——已经牢牢锁定了通往未来的道路。然而,就在AI系统变得越来越庞大、能耗越来越高、对数据依赖越来越强的同时,一个曾被边缘化的疑问重新浮出水面:智能是否必须建立在硅片之上?有没有可能,真正的下一代智能,其根基不在金属与电流,而在活生生的细胞与突触之中?
这一问题并非空想。在全球多个前沿实验室里,科学家正尝试将活体神经元与电子设备深度融合,构建一种被称为“合成生物智能”(SyntheticBiologicalIntelligence)的新范式。它不依赖预设的代码,而是让生物神经网络在与环境的互动中自主学习、适应甚至“思考”。
一场没有身体的电子游戏
想象这样一个场景:在一间恒温、无菌的实验室里,几万个来自老鼠胚胎或人类干细胞的脑细胞被小心地安置在一个指甲盖大小的芯片上。它们没有眼睛去看屏幕,没有手去操控手柄,甚至没有一个完整的身体——却成功地玩起了上世纪70年代风靡全球的电子游戏《Pong》(乒乓)。更令人惊讶的是,它们不仅会玩,还在几分钟内学会了如何打得更好。
这并非科幻小说中的桥段,而是2022年由澳大利亚初创公司CorticalLabs联合多所高校发表在《Neuron》期刊上的一项真实实验。研究团队将这套系统命名为“DishBrain”(培养皿大脑),并首次证明:即使脱离了生物体,活体神经元也能在虚拟环境中感知信息、做出反应,并通过反馈机制实现学习。这一发现不仅挑战了我们对“智能”和“意识”的传统理解,也为未来神经科学、药物研发乃至新型计算范式打开了全新的可能性。
神经元如何“看见”和“移动”?
要理解这项实验的精妙之处,首先需要了解科学家是如何让这些“无眼无手”的神经元与游戏世界互动的。
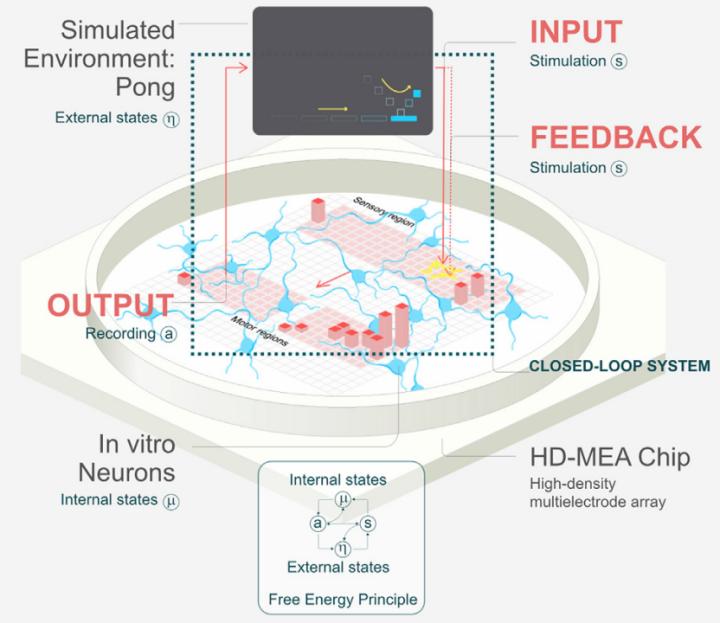
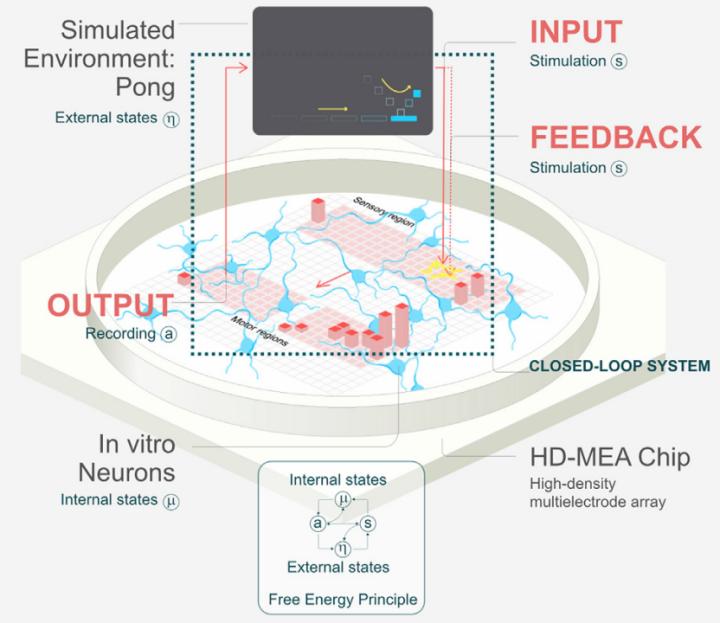
实验的核心是一个高密度微电极阵列(HD-MEA)——一块布满数千个微型电极的硅芯片。研究人员将从小鼠胚胎皮层或人类诱导多能干细胞(hiPSCs)分化而来的神经元接种在这块芯片上。几天后,这些神经元彼此连接,形成一个自发放电、具有基本网络结构的微型“脑组织”。
游戏本身是简化版的《Pong》:屏幕上有一个垂直移动的“球拍”和一个来回弹跳的“球”。目标很简单——用球拍击中球,不让它飞出屏幕。
那么,神经元如何“知道”球在哪里?又如何“控制”球拍?
答案在于电信号的编码与解码。当球出现在屏幕左侧时,芯片左侧的一组电极会向神经元发送一串特定频率的电脉冲;若球在右侧,则由右侧电极发送信号。这种设计模拟了大脑接收外部感官输入的方式——只不过在这里,视觉信息被直接转化为电刺激。
至于“控制”球拍,则依赖于对神经元活动的实时读取。研究人员将芯片划分为两个“运动区”:一个区域的活跃程度对应球拍向上移动,另一个则对应向下。系统持续监测这两个区域的放电频率,并据此调整球拍位置。整个过程构成了一个闭环:神经元接收信息→产生反应→系统执行动作→游戏结果反馈回来→神经元再次调整。
学习的秘密:讨厌“意外”的大脑
真正让这项实验脱颖而出的,不是神经元能玩游戏,而是它们学会了如何玩得更好。在短短5分钟内,接受有效反馈的神经元群体显著延长了每次游戏的回合数——这意味着它们成功提高了击球准确率。
关键在于反馈机制的设计。研究团队没有使用传统的“奖励/惩罚”标签,而是巧妙地利用了神经科学中的一个前沿理论——自由能原理(FreeEnergyPrinciple)。
该理论由英国神经科学家卡尔·弗里斯顿提出,核心观点是:所有自组织系统(包括大脑)都倾向于最小化“预测误差”或“意外感”。换句话说,大脑天生厌恶不确定性。当现实与预期不符时,系统会感到“惊讶”,并主动调整内部模型以减少未来的“惊讶”。
在DishBrain实验中,这一原理被转化为两种截然不同的电信号:
如果成功击中球,系统返回一段规律、可预测的电信号(例如固定频率的脉冲);
如果未能击中球,系统返回一段随机、混乱、不可预测的噪声信号。
对神经元而言,混乱信号就是“意外”。为了减少这种不适感,它们会自发调整放电模式,试图让球拍更准确地拦截球,从而避免接收到混乱反馈。这种自我优化的过程,本质上就是一种无监督的学习。
为了验证这一点,研究团队设置了多个对照组:一组神经元只接收输入但无反馈(开环系统),另一组则完全不包含活细胞。结果明确显示,只有处于闭环反馈中的神经元才表现出学习能力。这一对照排除了随机波动或设备误差的可能性,确证了学习行为源于神经网络对环境反馈的适应。
本文链接:/article/心智观察所-离体脑细胞学会打游戏-智能从何而来
转载请注明出处,谢谢!